Using SQL Source Control to Filter Out Unwanted Items
Everything written on this site is how to get a database change automatically pushed up through the environments. But that was for the entire database. There are some parts of the database where they shouldn't be put under source control or shouldn't be promoted. Now you are probably thinking, "that doesn't make a whole lot of sense, I should always deploy the entire schema all the time." First off, Mr./Mrs. hypothetical reader, that is a very extremist view, secondly, there are instances where deploying the entire schema shouldn't happen.
Below are some of the scenarios I have run across since I started automating my deployments.
- Users - At Farm Credit Services of America each environment has its own service account. This way the account that can access test cannot access production. It helps give the security and risk people a nice feeling. So it doesn't make much sense to include users in source control or as part of the deployment.
- Backup Tables - Imagine you are working in a legacy system with a lot of tables you have no idea what they do. The business is demanding a change to the table but you are unsure if the change will work. So you create a table, something like [TableName]_ Backup_10122016. That way you can get back to where the data was prior to the change or if you need to do some A/B comparisons. That table shouldn't be included in source control or deployed. By default, if a table is not in the package being deployed it will be removed, well removing it during a deployment really defeats the purpose of having that table in the first place.
- Tables in Test or Staging Schemas - QA really likes static data. It helps ensure tests run consistently. They might create a table to store some test data which will be used in an automated test. That table might only exist in one environment. Deleting that table during a deployment will result in "the look" from the QA people. Everyone knows that look. We got it from teachers for saying a smart-ass comment in class.
SQL Source Control Filtering
Redgate's SQL Source Control has this covered. It is possible to create a filter using the GUI. This filter will then be saved in the version control repo as a .scpf (SQL Compare Filter) file. That file will be read by their DLM automation tooling when deploying a database change and exclude those items from the deployment.
Fun Fact: The .scpf file is nothing more than an .xml file. Once you know the schema you can easily modify it without using the SQL Source Control GUI. Just be careful and test the changes.
Using the Filtering
The most common scenario I have run across is excluding tables in a specific schema or if they match a certain naming standard. These tables are typically created for a backup or for testing. My advice is work with your team on establishing a standard everyone is familiar with. The easiest for my team was placing all the tables in the test schema and excluding any table in the schema. The schema itself would be checked into source control, just not any tables in that schema.
Setting Up Your First Filter
In this example, we will be creating a backups schema and excluding any table found in that schema from source control.
- Create the schema Backups
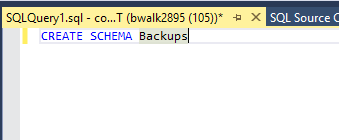
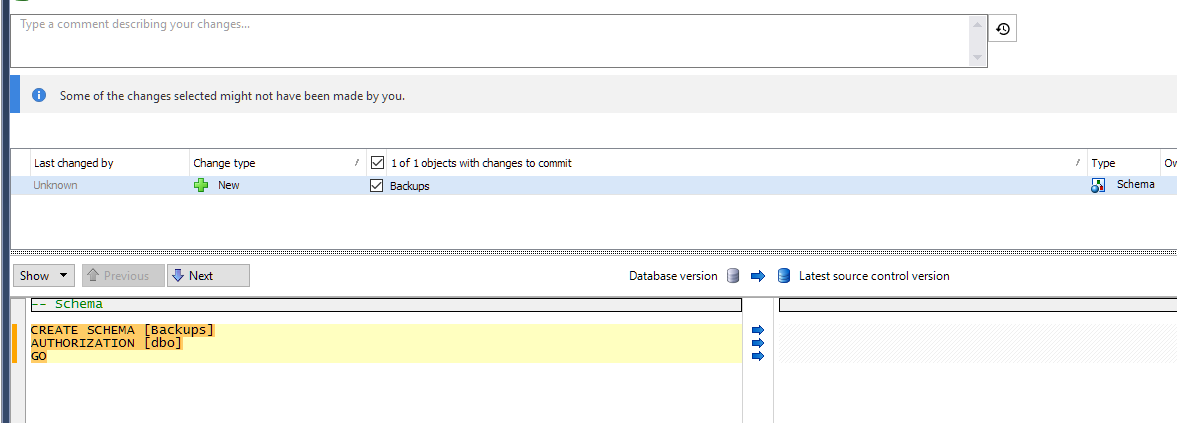
- As you can see, that schema can now be checked into source control
- Now create a table in that schema
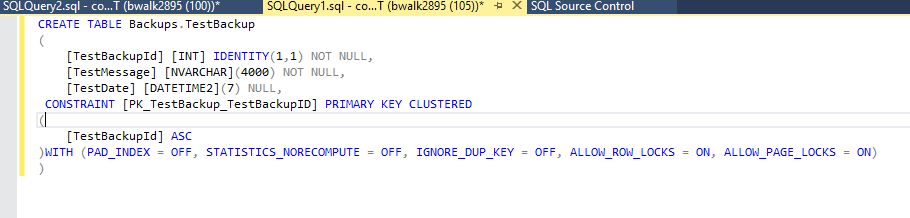
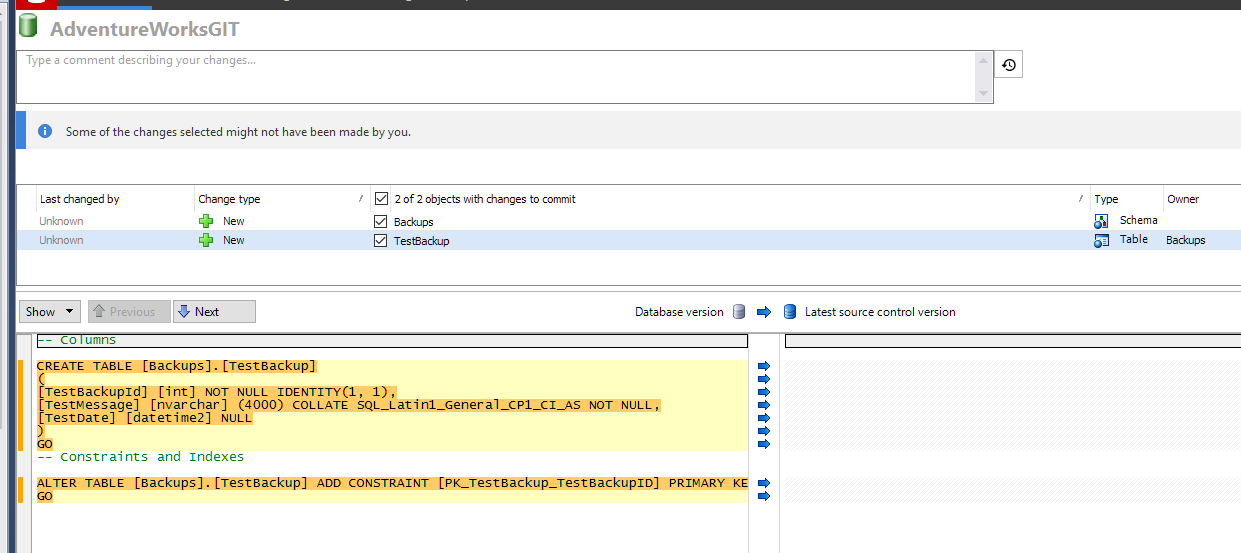
- As you can see, source control is going to attempt to check in that table as well. This is what we want to exclude
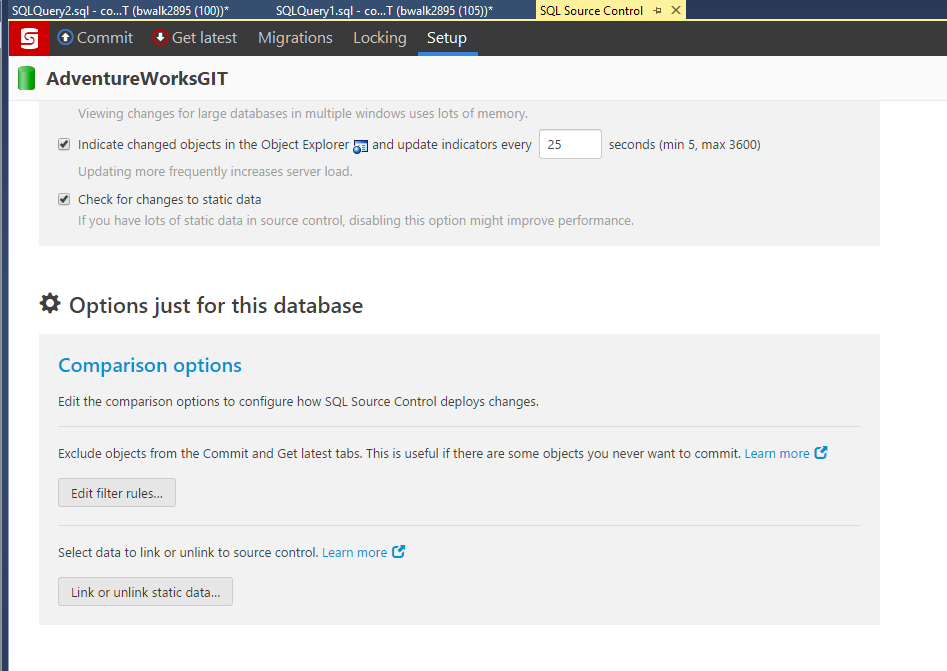
- In SQL Source Control GUI, click on the setup tab and scroll down to the area "Options just for this database" section. Click on the Edit Filter Rules... button.
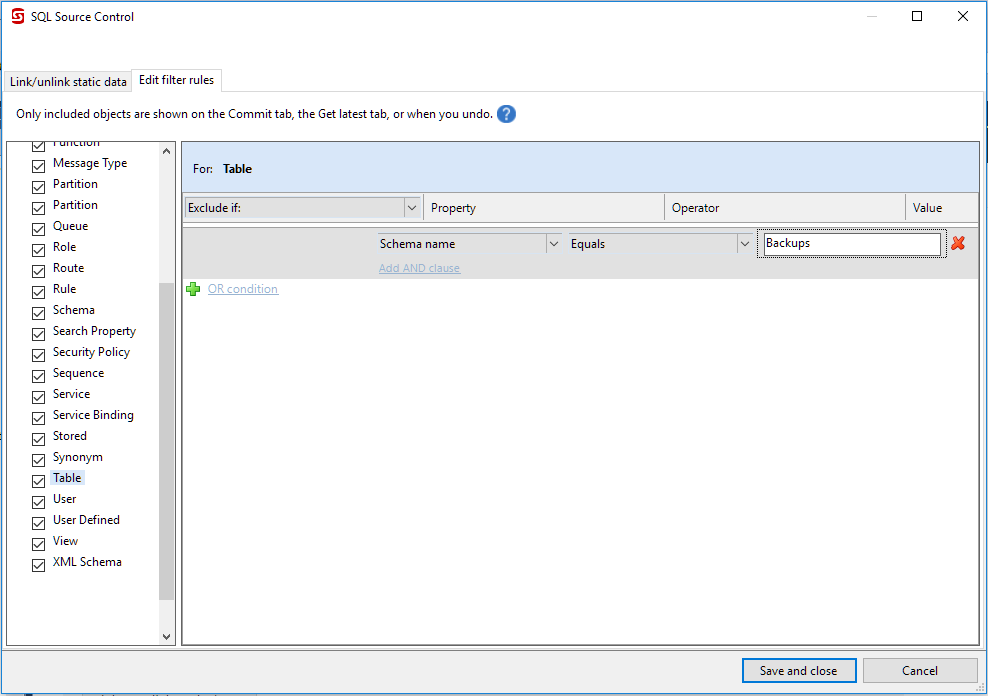
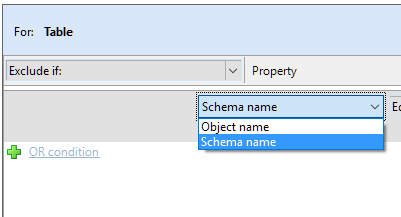
- A modal window will appear showing you all the filters supported. In this example, we are interested in filtering out any table in the Backups schema. Scroll down the left and select table. Then change the first option to say "Schema Name," the second option will be changed to "Equals" and type in Backups. Click save and close when done.
- Now go back to the commit tab. As you can see now, the test table no longer appears in the checkout. You will also get a warning message indicating there are items being excluded by the filter. Go ahead and check in the schema and filter. We want to check in the schema because other people on the team can take advantage of it on their dedicated instances.
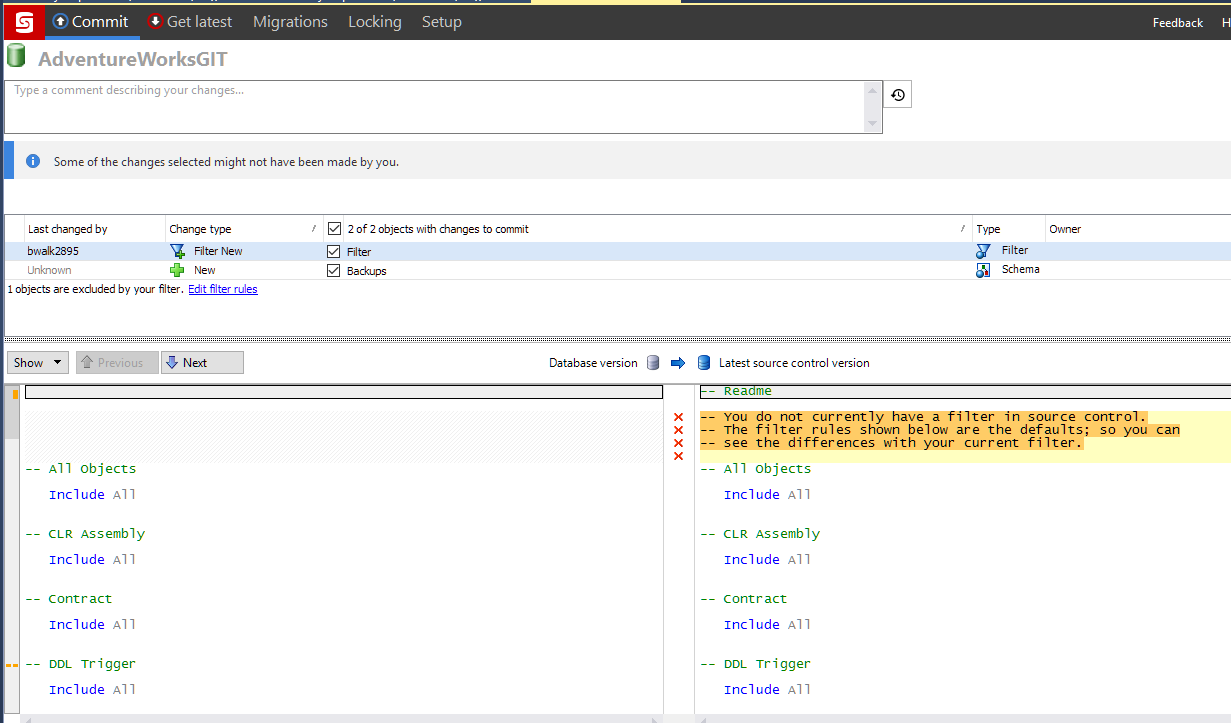
- After checking in, you can see the filter and new schema appear in the change log.
- Taking a peek at the file will show you it is just XML.
Advanced Usages
The filtering engine supports a lot of different ways to create a filter. For tables alone, you can filter by the following
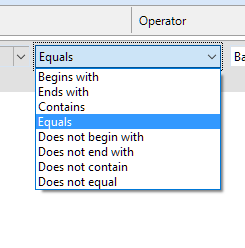
The name comparison supports the following options
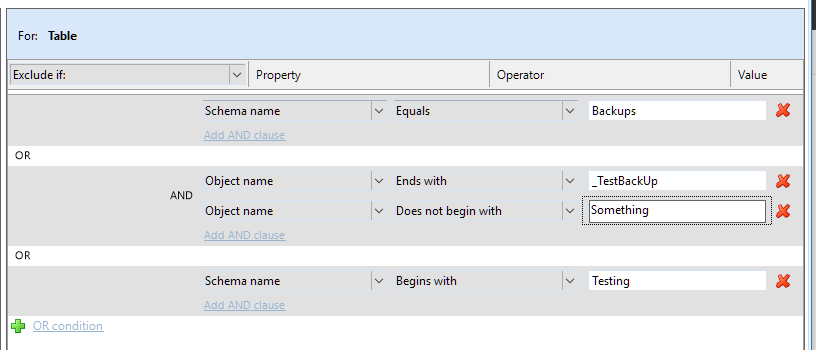
The filters can get fairly complex using a combination of ORs and Ands.
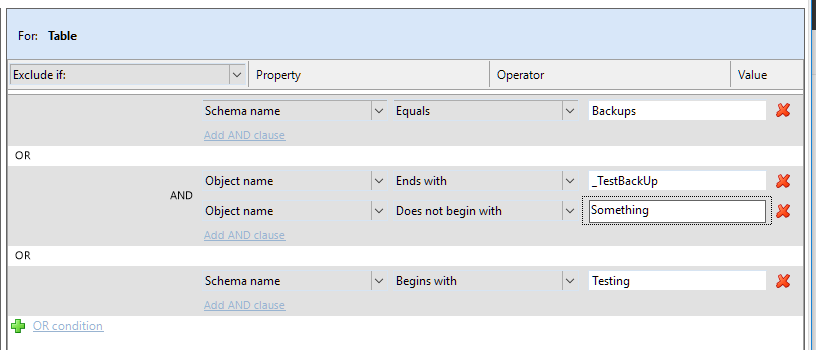
The GUI makes it very easy to build out as complex or as a simple filter as you would like.
Conclusion
This is a very easy to use feature in Redgate's SQL Source Control, but it is very powerful. It provides you and your team the necessary flexibility to exclude items you don't want as part of your automated database deployment pipeline. Without this feature, I don't think it would be possible for Farm Credit Services of America to implement automated database deployments without having to jump through some serious hoops.
I want to finish up with a story. When I put a legacy database into version control it was filled with a lot of backup tables and test tables. I did not want to delete those tables (I dislike "the look" from QA), I couldn't just move them without having the QA person update a lot of their tests. But, that database needed to get into source control. I ended up creating a rather complex filter to exclude out all the unwanted tables. RedGate's SQL Source Control and DLM Automation Suite handled it like a champ.