Using Gitflow and Redgate DLM Automation for Continuous Delivery
One of the key reasons to use Redgate's Tooling is to deliver value faster to the business. In order to do that, it is important to have a branching policy in place.
This is only possible with a local database and Redgate's tools. Prior to implementing their tools, all developers shared the same database, which made branching very, very difficult. A required column could be added to a key table, in a shared database model with no source control that would require all code in all active branches to insert/update data into that column. Local databases with Redgate's SQL Source Control solved that problem for my team. But we ran into a new challenge. One that would require my team to implement a modified version of the Gitflow branching strategy both locally and on a server.
But sometimes a local database is not enough. Sometimes, a bigger solution is needed.
Background
My team is responsible for one of the loan origination systems at Farm Credit Services of America. At the time of this writing, we are currently working on the next generation of that system. The project started two years ago, and since that time we have had five major releases to our users.
At the start of the project, we didn't have to worry about a branching strategy or how to handle production support. Check everything into master and call it good. Worried about breaking the test environment, use a feature branch until the feature is ready to check into master.
During this time, one of the developers on my team said: "Hey we should use Gitflow." My response to that was "hell, no that looks way too complex." My tune has drastically changed since then.
As the project matured and more and more people started using the application my team and I started running into the same problem many other teams have run into. How can we release minor features and bug fixes while still working on major releases?
My team's goal is continuous delivery and eventually continuous deployments. We are always shooting for that goal. But, we also need to be realistic and work with our business owners. The business does not want half baked features going out to the users. Being a loan origination system means at some point we will be handing over money to a customer, we sort of want to have accurate information. In one case we had a major release ready to go in March but the business asked us to hold off until June because January through May is Farm Credit Services of America's busy season. Dropping a major release while people are stressed out would have been a terrible, terrible idea. We had to put that release on ice while still delivering bug fixes and minor features to our users.
Modified Gitflow
Gitflow is a branching strategy first proposed by Vincent Driessen. My team uses a modified version of what he proposed.

Source: Altassian Gitflow Documentation
Master Branch
The master branch represents what is about to go to production, or after we release what is currently in production. This branch should always be ready to go to production by the end of a business day. Ideally sooner if a major bug is found. Any hotfixes added to master are merged down to development as soon as they pass testing and verification. The SLA on the master branch should be as close to 100% as possible.
Development Branch
The development branch is where all the work for a major release goes. This branch is constantly in flux and may or may not be broken. Once all the functionality in development is tested and verified development will be merged into master. The merges into master are rare, perhaps 6-10 times a year. The merges from master into development are frequent, anywhere from 1 to 4 a week. The SLA on the development branch is somewhere around 80-90%.

Source: Altassian Gitflow Documentation
Feature Branches
A feature branch can be created off of master or development. Once the feature is complete it can be merged back into the source branch (if it is branched off master, it is merged back to master). Most feature branches originate from the development branch.

Source: Altassian Gitflow Documentation
Pull Requests
No one can directly merge into master or development and push that up to the server. They must use a pull request. We use Visual Studio Team System (VSTS or VSO), and it has branch policies to enforce this.
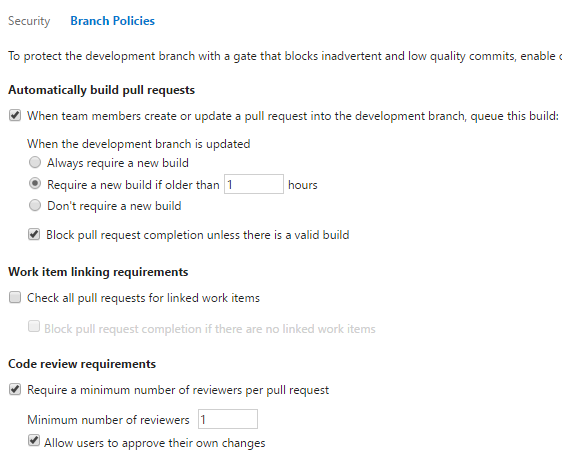
Our branch policy forces a CI build to be complete prior to approving a pull request. That means with feature branches and branch policies we can ensure, at the bare minimum, the following is true before the code gets merged into master.
- Code Builds
- All C# unit tests pass
- All JavaScript unit tests pass
- Database package is built (all SQL in source control is valid)
- Someone else looks at the changes
Release Tags
Right before each release I will tag the commit going to production. This helps us with debugging because we can always checkout the code using the tag and see exactly what code is in production. A tag is different than a branch because a tag represents a particular commit of a branch at a point in time. While a branch may be modified. Gitflow recommends creating a branch. We find tags work better
New Feature Development Workflow
When working on a major new feature here is the typical workflow my team uses.
- Create feature branch off of development
- Once feature is complete create pull request to merge into development
- Feature is tested and verified in development branch
- Multiple features are bundled together for a release
- Development is merged into master
- Release is tested and verified through automated tests in master
- Final commit into master before release is tagged
- Master is released to production
Bug Workflow
When working on a bug or a minor feature here is the typical workflow my team uses.
- Create bug fix branch off of master
- Once bug fix is complete create pull request to merge into master
- Bug fix is tested and verified in development branch
- Final commit into master before release is tagged
- Master is released to production
The Perils of Rolling Back
Most teams at Farm Credit Services of America have their deployments from the CI builds setup in a very straight-forward way. Most code follows this path to production.
- Code is built on VSTS and pushed up to Octopus Deploy
- Octopus Deploy deploys the code to a development server
- Tests are run in development
- Tests pass, Octopus Deploy deploys to a QA server
- Code is verified by Business Owners and QA, Octopus Deploy deploys to a pre-prod server and the last verification occurs
- Octopus Deploy deploys to production
Only code checked into master is being deployed. This means there is only one instance of the application in each environment. For example, if it were a website its address would be:
https://testfakeserver/[ApplicationName]/UI
This approach led to numerous problems on my team because we wanted to be able to fix production and have code not go to production that wasn't ready. Using that single instance model, let's say we found a critical bug in production, but all the code for the next release is deployed all the way up to pre-production for a week of verification by the business (it happens). What ends up happening is the pre-production environment is rolled back to match production, the hotfix is then deployed.
Rolling back is a terrible thing to do, especially when you are trying to put out a fire.
You never know if everything is truly rolled back. And you end up thrashing the hell out of your database. Rolling back schema changes is easy with Redgate DLM Automation Suite, rolling back data is very, very hard. A lot of times developers just give up and have the DBAs to a full backup and restore from production. That is not acceptable with production. I can't tell a user, hey remember that loan application you spent a half hour creating? Well, guess what, you get to do it again!
Rolling back takes time, hours or in some cases, even a day.
I wanted a clear path to production. My goals for that path were:
- Never rollback
- Getting to pre-production should take less than 20 minutes. If needed, a fix to production could be deployed in less than 30 minutes.
- The deployment will go through every environment, there will still be automated testing to ensure hotfix does not break something else.
- Code in this path should match production except for the delta consisting of a hotfix or a set of hotfixes
Beta Environment
The solution is simple. Create a new instance of the application in each of the lower environments (dev, QA, pre-prod). This new instance is called [ApplicationName]beta. So the URL would be:
https://testfakeserver/[ApplicationName]Beta/UI.
Fun Fact: Beta was chosen because we give this URL to our testers. It is very confusing to tell the tester to test in "QA Development" or "Development Development" or "Pre-Prod Development."
The CI build for the development branch would deploy to the beta instance.
The CI build for the master branch would deploy to the non-beta instance.
Fun Fact: When I worked at TelventDTN (now Schneider Electric) my team had a similar setup, two development environments. But which one was a reflection of production changed all the time?
The solution is simple, but the devil is in the details. The loan origination system consists of many parts
- WebApi
- UI
- Database
- Windows Service
Each piece of the application has a separate project within Octopus Deploy. This was done because only very rarely will the entire application suite be deployed to production at the same time. In most cases for a hotfix, it is a change to the WebApi.
Remember when I told you about how my team at TelventDTN/S.E. had a similar setup? You should, it was less than 10 lines sentences ago. Well, our application had an easier setup, a UI, and a Database. Keeping the databases in sync was a time-suck. It was manual and prone to errors.
This is where the tooling provided by Microsoft (VSTS for builds), Redgate (DLM Automation Suite and SQL Source Control), and Octopus Deploy makes this possible. It is possible to do it without these tools, but it is a lot harder. Kind of like steering your car with your knees.
Tooling Usage to Accomplish Beta Environment
The good news is when this idea initially popped into my head all the tooling was already in place. This made setup relatively easy.
Octopus Deploy
Octopus allows you to clone projects. Octopus Deploy's handy documentation shows how this in done. Here is a screenshot for those of you who don't like to read. I cloned the project for each of the components of the loan origination system and added the "Beta" prefix.

VSTS Builds
In VSTS it is possible to clone a build using the build explorer. You just need to right click on the build name and select clone build. After cloning the build it was only a matter of changing around a few variables in the build steps to point to the new "Beta" projects.
Database Setup
As stated in an earlier article, Redgate DLM Automation Suite does not support the creation of a database. No problem. I simply did a backup and restore of the database in each of the environments, in this case, the name of the database had the beta moniker made as a suffix. Then I setup Octopus Deploy to deploy to the beta version of the database.
Local Databases, Redgate Tooling, and Branching
Without Redgate tooling, none of this would be possible. Let's look at a developer's local database with SQL Source Control for the first example.
A developer has been working off of the development branch for a while. Their local database reflects what is in development (beta). For the most part, they have new tables, new columns and updated stored procedures and views. A production bug comes in they have to fix.
The developer switches over to the master branch using the GIT GUI of their choice. I prefer GITKraken.
After that, the developer can right-click on their database in SQL Server Management Studio and get latest changes.
As you can see from this image there are a lot of differences that need to be applied.
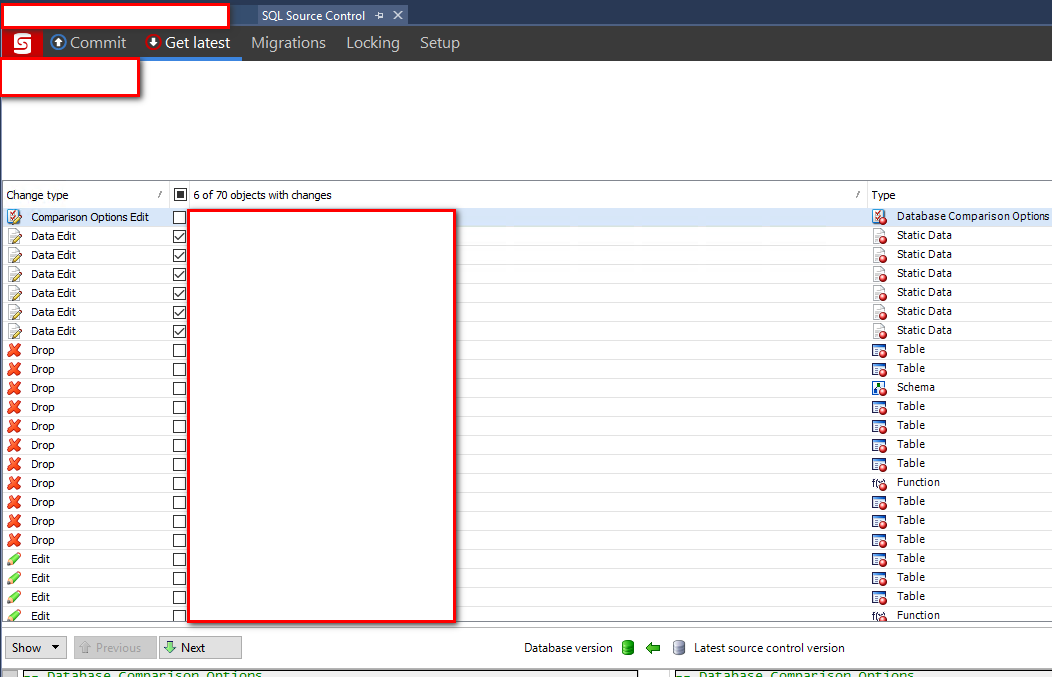
This step must be done to ensure the code is using the latest version of the database schema matching production. Imagine trying to do this without the tooling? You would have to manually determine the delta and apply the necessary changes.
After getting the database schema up to date they can use SQL Data Compare to copy down a test case or two to help debug.
Side Note: It is possible to change your connection string to point to a non-local database. That is very unwise as during debugging or testing you might accidentally delete data. Or you might now have rights to update the data. Trust me, having a local copy makes your life a lot easier. Copy data whenever possible. I would rather spend 5 minutes doing that than explaining why I messed something up because I connected to the wrong database.
After the bug is fixed then the developer can switch back over to development branch and reapply the changes that were dropped following a simple process.
Side Note: For very long release cycles you might end up in a situation where the delta between master and development is too large and the changes are too destructive. In this case create a copy of the database locally, one for master the other for development. Just be sure to remember to switch your connection string.
Database Servers, Redgate Tooling and Branching
The work in development has finally reached the point where it can be released to production. Great. Now it is time to merge development into master. This means all the database changes sitting in the development branch will be merged into master and deployed through the environments. In this setup, the deployment will be tested at least three times before it gets to production. That is, assuming you have four environments. Redgate's DLM Automation Suite treats the merge like any other check-in. Sure there a lot more changes, but so far we haven't run into anything that prevents a deployment.
If there are any destructive changes or merge conflicts applied incorrectly (trust me it happens) they should be detected by automated testing (UI or Service Level) or just plain old manual verification. By the time the production release happens there should be little question as to what is going to happen.
Git Pro Tip: Merge master into development first. When you merge development into master the commit created during the merge of master into development will be used. This will make your life a lot easier.
Business Reaction
The reaction from the business to this setup has been very positive. My team is able to deliver bug fixes almost as soon as they are discovered. Or a new minor feature can be added to help another team solve a problem.
Since our last major release in June my team has done a release about every 10 days to production. The releases range from fixing a couple of bugs and adding a new feature to fixing several dozen bugs. This enables us to get feedback faster.
This setup also helps us work on a large release without the worry of inadvertently releasing a bug or a partially completed feature to production.
Alpha Environment
This setup has been so well received by the business we have even created an alpha environment to implement features that we know could break what is in the beta environment. Or we want to have a way to conduct A-B testing. For example, we integrated with a new version of a service. The alpha environment implemented the new version while the beta environment stayed on the previous version. The only delta between the two environments was the new version. We were able to conduct A-B testing between the two.
A couple of important notes. The alpha environment is not always used. And we change which branch auto-deploys to it in VSTS.
At some point in the future, I would like to update our process to automatically spin up an environment. All the tooling is there, we just need to spend some time working out all the kinks.
The Downside
It is not all rainbows and sunshine. There are downsides.
For starters, it can be confusing at times for testers and developers. We came up with a system of marking each story on our Scrum/Kanban Board indicating which environment the change should go in. Developers have also included notes as to where the story should be tested.
Also, we have had to keep up with merging master down into development. We settled on when the bug fix has made it past the testers. There is no need to merge a non-verified story into development due to the natural churn of development/test/bug fix/test. If there are several bug fixes in flight we wait until the last one makes it past the testers.
Conclusion
This setup is how my team is able to continuously deliver value to the business while maintaining long release cycles. None of this would be possible without the tooling provided by Microsoft, Octopus Deploy, and especially Redgate. Without having a way to automatically deploy database changes this whole idea would implode on the launch pad.